I am going to write a series of a few posts about the transition from the basic AWS ElasticBeanstalk SQS integration to the more generic, reactive model.
Transition means that we have a current state that we want to change. So let’s start with the basic AWS SQS integration.
Amazon SQS is a HTTP-based managed service responsible for handling message queues. It offers two kinds of queues: standard queues (maximum throughput, at-least-once delivery) and FIFO queues (preserving messages order, exactly-once delivery).
Just for the record – it is possible to integrate with AWS SQS using the SDK in many languages (Java, Ruby, .Net, Php, etc.) which give you both synchronous and asynchronous interface. What is more, SQS is also Java Message Services (JMS) 1.1 compatible (Amazon SQS Java Messaging Library).
Let’s assume our application performs some sort of operations that can take a bit longer to complete and can be done asynchronously in the background. However, they are mostly triggered as a result of user interaction with the system. These can be sending an email, generating and sending invoices to the clients, processing images, generating huge reports.
The first, naive implementation could be to spawn the local, asynchronous task and handle the job there. The drawbacks of such solution are obvious: it consumes local resources that could be used for handling more user requests, it is hard to scale, it is not manageable, etc.
The better solution is to introduce some kind of middleware layer that allows distributing the work among the workers.
Therefore we deploy the system in the Elastic Beanstalk environment with the following setup:
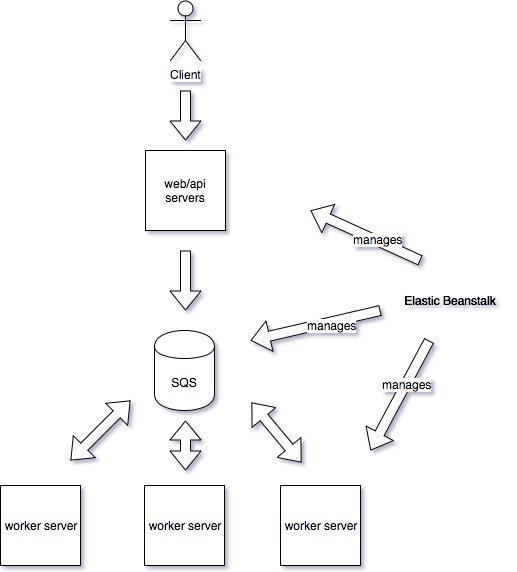
The web/api servers process user requests and offload the background tasks to the SQS queue using the AWS SDK SQS Api. Elastic Beanstalk has the daemon process on each instance that has the responsibility to fetch the messages from the SQS queue and push them to the worker server. The worker servers only expose the REST POST endpoint that is used by the daemon process to push the messages. The whole setup can be fairly configured using AWS WEB console and also monitoring is quite decent. There is also one feature that is quite hidden but worth mentioning. The Elastic Beanstalk daemon process makes sure that the worker servers do not become overwhelmed and it POSTs messages to them only if they are capable of processing them. The limitations are as following: only one SQS queue can be used – all messages are put into one queue and are processed sequentially and the system gets tightly coupled to AWS environment (Elastic Beanstalk).
What I am suggesting in this post is still sticking to the SQS queues and keeping the worker servers but changing the way the messages are put into workers. Instead of relying on Elastic Beanstalk daemon process let’s implement reactive streams on each of the servers that are connected to the SQS queues.
What we gain in such solution is the ability to use multiple queues, if we properly implement the integration layer we are not that tightly coupled to the AWS infrastructure too. This is in regards to the “reading” part. In the following posts, we will see what advantages we get if we also implement the “writing” part using the reactive streams.
Before we dive into the details, let’s quickly introduce the term reactive streams and reactive programming. Both terms are strictly connected.
Generally, reactive programming is programming model that deals with asynchronous streams of data. It is also a model in which components are loosely coupled. Actually, it is nothing new. We have seen event buses for a long time already. Also if we look at the user interaction with the application or website it is mostly stream of click or other actions. The real changer though is the way we handle those data streams.
Instead of repeating the theory and well-known phrases about reactive programming I will try to quickly show the difference between reactive and proactive programming on a simple examples.
Imagine we have a switch and a light bulb. How would we program switching on the bulb? The first solution is obvious. The switch knows what light bulb it controls. It sends the command to the specific light bulb. The switch is proactive and the light bulb is passive. It means that the switch sends commands and the bulb only reacts to those commands.
This is how we would program it:
import LightBulb._
case class LightBulb(state: Int, power: Int) {
def changeState(state: Int): LightBulb = this.copy(state = state)
}
object LightBulb {
val Off = 0
val On = 1
}
case class Switch(state: Int, lightBulb: LightBulb = LightBulb(Off, 60)) {
def onSwitch(state: Int): LightBulb = lightBulb.changeState(state)
}
The limitations are obvious. The code is tightly coupled. The switch needs to know about the bulb. What if want it to control more bulbs? What if we want one switch to control the light bulb and the wall socket? What about turning on the same light bulb using two different switches? The tightly coupled code is not open for extensions.
What is the reactive solution to this problem?
The switch is responsible for changing its state only. The light bulb listens to the state changes of any switch and based on this modifies its state. In this model the bulb is reactive – changing its state as a reaction to the switch state change and the switch is observable – its state is being observed by other components (bulbs, sockets, etc.)
The reactive solution:
import LightBulb._
case class Notification(state: Int)
trait Observer[T] {
def update(notification: T)
}
trait Observable[T] {
private var observers: List[Observer[Notification]] = Nil
def addObserver(observer: Observer[Notification]): List[Observer[Notification]] = observer :: observers
def removeObserver(observer: T): Unit = observers ::= observer
def notifyObservers(notification: Notification): Unit = observers.foreach(_.update(notification))
}
case class LightBulb(state: Int, power: Int) extends Observer[Notification] {
override def update(notification: Notification): LightBulb = this.copy(state = notification.state)
}
object LightBulb {
val Off = 0
val On = 1
}
case class Switch(state: Int) extends Observable[LightBulb] {
def onSwitch(state: Int): Switch = {
notifyObservers(Notification(state))
this.copy(state = state)
}
}
object SwitchBulb {
val lightBulb = LightBulb(Off, 60)
val switch = Switch(Off)
switch.addObserver(lightBulb)
}
The end result of those two approaches is the same. What are the differences then?
In the first solution, some external entity (switch) controls the bulb. To do so it needs to have the reference to the bulb. However, in the reactive model, the bulb controls itself. Another difference is that in the proactive model, switch itself determines what it controls. In the reactive model, it does not know what it controls, it just has a list of items that are interested in its state changes. Then those items determine what to do as a reaction to the change.
The models look similar, actually, they mirror each other. However, there is a subtle but really important difference. In the proactive model, components control each other directly while in the reactive model the components control each other indirectly and are not coupled together.
The reactive approach let us build the systems that are:
- message driven
- scalable
- resilient
- responsive
In the next post of this series I will present the actual integration with AWS SQS using Akka Streams and Alpakka AWS SQS Connector.
Stay tuned.