I’ve been doing programming in Scala for more than 2 years already. I think I can position myself somewhere here:

From time to time I look at Scala Exercises or similar pages where I usually find some things that I do not know yet.
In this blog I would like to share some of the Scala features I found interesting recently.
Collections
Let’s start with Scala Collections framework. Scala Collections is the framework/library which is a very good example of applying Don’t Repeat Yourself principle. The aim was to design the collections library that avoids code duplication as much as possible. Therefore most operations are defined in collection templates. The templates can be easily and flexibly inherited from individual base classes and implementations.
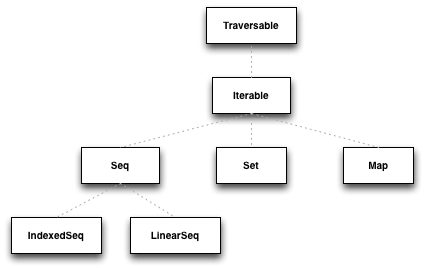
Avoid creating temporary collections
val seq = "first" :: "second" :: "last" :: Nil val f: (String) => Option[Int] = ??? val g: (Option[Int]) => Seq[Int] = ??? val h: (Int) => Boolean = ??? seq.map(f).flatMap(g).filter(h).reduce(???)
In this sequence of operations a temporary, intermediate collection is created. We do not need those collections implicitly. They only unnecessarily take heap space and burden the GC. The question is why those intermediate collections are created. The answer is because the collections (except Stream) transformers like a map, flatMap, etc. are “strict”. It means that the new collection is always constructed as a result of the transformer. Obviously, there are also “non-strict” transformers available (lazyMap). But how to avoid creating those temporary collections why still using the “strict” transformers? There is a systematic way to turn every collection into a lazy one which is a view. This is special kind of collection that implements all transformers in a lazy way:
val seq = "first" :: "second" :: "last" :: Nil val f: (String) => Option[Int] = ??? val g: (Option[Int]) => Seq[Int] = ??? val h: (Int) => Boolean = ??? seq.view.map(f).flatMap(g).filter(h).reduce(???)
Now the temporary collections are not created and elements are not stored in the memory.
It is also possible to use views when instead of reducing to a single element the new collection of the same type is created. However, in this case, the force method call is needed:
val seq = "first" :: "second" :: "last" :: Nil val f: (String) => Option[Int] = ??? val g: (Option[Int]) => Seq[Int] = ??? val h: (Int) => Boolean = ??? seq.view.map(f).flatMap(g).filter(h).force
When transformation creates a collection of different type, instead of force method the suitable converted can be used:
val seq = "first" :: "second" :: "last" :: Nil val f: (String) => Option[Int] = ??? val g: (Option[Int]) => Seq[Int] = ??? val h: (Int) => Boolean = ??? seq.view.map(f).flatMap(g).filter(h).toList
Calling toSeq on a “non-strict” collection
When Seq(…) is used the new “strict” collection is created. It might look obvious that when we call toSeq on a “non-strict” collection (Stream, Iterator) we create a “strict” Seq. However, when toSeq is called actually we call TraversableOnce.toSeq which returns Stream under the hood which is “lazy” collection. This may lead to hard to track bugs or performance issues.
val source = Source.fromFile("file.txt")
val lines = source.getLines.toSeq
source.close()
lines.foreach(println)
The code seems to look good however when we run it throws IOException complaining that the stream is already closed. Based on what we said above it makes sense since the toSeq call does not create a new “strict” collection but rather returns the Stream. The solution is to either to call toStream implicitly or if we need a strict collection we should use toVector instead of toSeq.
Never-ending Traversable
Every collection in Scala is Traversable. Traversables among many useful operations (map, flatMap) have also functions to get the information about the collection size: isEmpty, nonEmpty, size.
Generally, when we call size on the Traversable we expect the get the number of elements in the collection. When we do something like this:
List(1, 2, 3).size
we get 3, indeed.
Imaging that our API function accepts any Traversable and the user provides us with Stream.from(1) value. Stream is also Traversable but the difference is that this is one of the collections which is lazy by default. As a result, it does not have a definite size.
So when we call
Stream.from(1).size
this method never returns. It is definitely not what we expect.
Luckily, we have a method hasDefiniteSize which says if it is safe to call size on the Traversable.
Stream.from(1).hasDefiniteSize //false List(1, 2).hasDefiniteSize //true
One thing to remember is that if hasDefiniteSize returns true, it means that the collection is finite for sure. However, the other way around is not always guaranteed:
Stream.from(1).take(5).hasDefiniteSize //fasle Stream.from(1).take(5).size //5
Difference, intersection, union
This example is self-explanatory:
val numbers1 = Seq(1, 2, 3, 4, 5, 6) val numbers2 = Seq(4, 5, 6, 7, 8, 9) numbers1.diff(numbers2) List(1, 2, 3): scala.collection.Se numbers1.intersect(numbers2) List(4, 5, 6): scala.collection.Seq numbers1.union(numbers2) List(1, 2, 3, 4, 5, 6, 4, 5, 6, 7, 8, 9): scala.collection.Seq
The union, however, keeps duplicates. It’s not what we want most of the times. In order to get rid of them we have a distinct function:
val numbers1 = Seq(1, 2, 3, 4, 5, 6) val numbers2 = Seq(4, 5, 6, 7, 8, 9) numbers1.union(numbers2).distinct List(1, 2, 3, 4, 5, 6, 7, 8, 9): scala.collection.Seq
Collection types performance implications
Seq
Seq most of the available operations are linear which means they will take time proportional to the collection size (L ~ O(n)). For example, append operation will take linear time on Seq which is not what we would expect. What is more, it means that if we have an infinite collection, some of the linear operations will not terminate. On the other hand, head or tail operations are very efficient.
List
| Time Complexity | Description |
|---|---|
| C | The operation takes (fast) constant time. |
| L | The operation is linear meaning it takes time proportional to the collection size. |
| Operation | Time Complexity |
|---|---|
| head | C ~ O(1) |
| tail | C ~ O(1) |
| apply | L ~ O(n) |
| update | L ~ O(n) |
| prepend | C ~ O(1) |
| append | L ~ O(n) |
Head, tail and prepend operations take constant time which means they are fast and do not depend on the collection size.
Vector
Vector performance is generally very good:
| Operation | Time Complexity |
|---|---|
| head | eC ~ O(1) |
| tail | eC ~ O(1) |
| apply | eC ~ O(1) |
| update | eC ~ O(1) |
| prepend | eC ~ O(1) |
| append | eC ~ O(1) |
head or tail operations are slower than on the List but not by much.
Conclusion
Always use a right tool for the job. Knowing the performance characteristics of different collection types we can choose the one that is the fastest for the kind of operations we do.
Type aliases
Type aliases in Scala allow us to create an alternate name for the type and (sometimes) for its companion object. Usually, we use them to create a simple alias for a more complex type.
type Matrix = List[List[Int]]
However, type aliases can be also helpful for API usability. When our API refers to some external types:
import spray.http.ContentType final case class ReturnValue (data: String, contentType: ContentType)
We always force users of our API to import those types:
import spray.http.ContentType
val value = ReturnValue("data", ContentType.`application/json`)
By defining the type alias in the base package we can give users the dependencies for free:
package com.dblazejewski
package object types {
type ContentType = spray.http.ContentType
}
import com.dblazejewski._
val value = ReturnValue("data", ContentType.`application/json`)
Another use case that comes to my mind is simplifications of type signatures:
def authenticate[T](auth: RequestContext => Future[Either[ErrorMessage, T]]) = ???
By introducing two type aliases:
package object authentication {
type AuthResult[T] = Either[ErrorMessage, T]
type Authenticator[T] = RequestContext => Future[AuthResult[T]]
}
We hide the complexity:
def authenticate[T](auth: Authenticator[T]) = ???
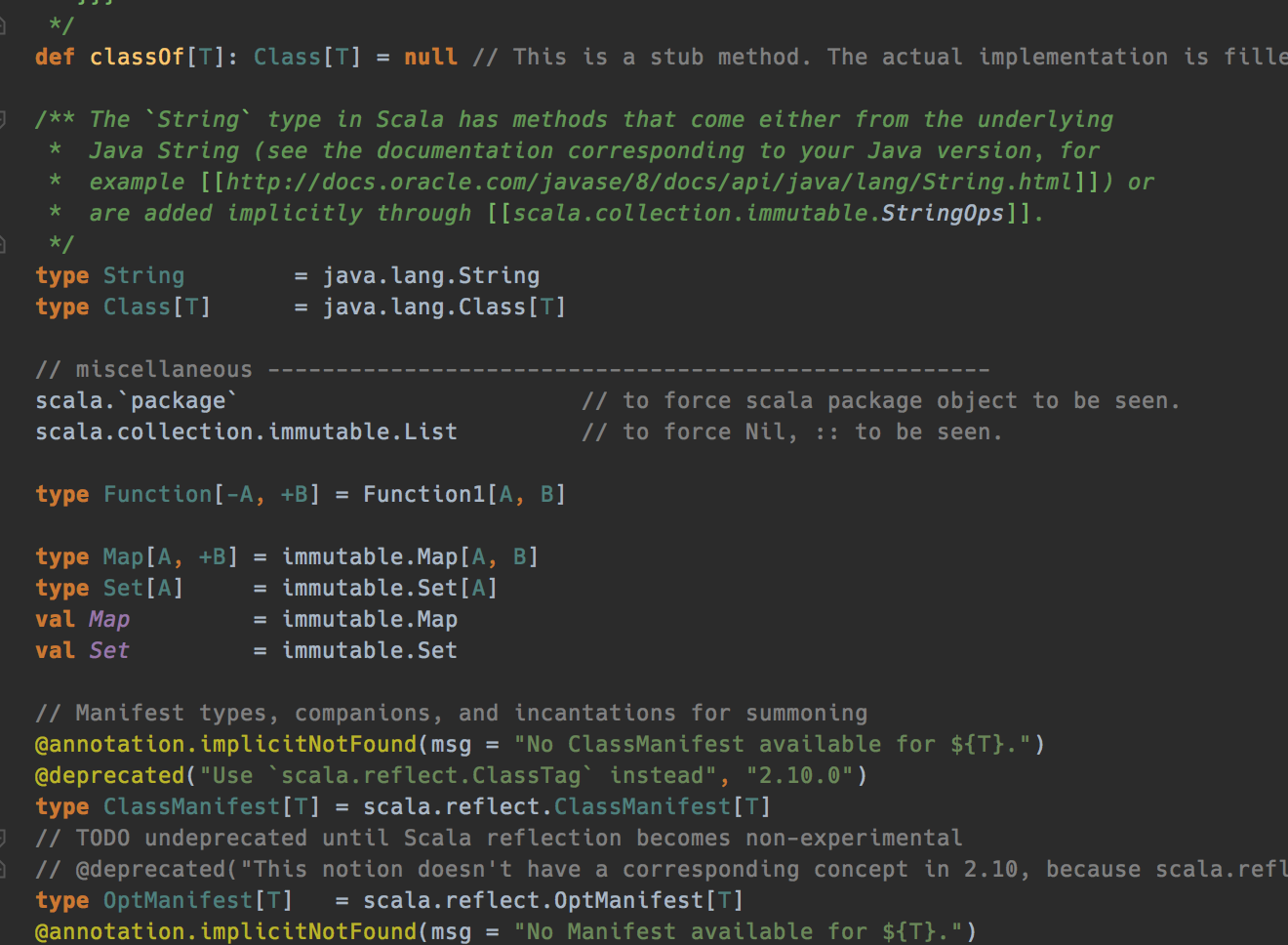
Actually, scala.Predef is full of type aliases:
Auto lifted partial functions
A partial function PartialFunction[A, B] is a function defined for some subset of domain A. The subset is defined by the isDefined method.
A partial function PartialFunction[A, B] can be lifted into a function Function[A, Option[B]]. The lifted function is defined over the whole domain A but the values of type Option[B]
Example:
val pf: PartialFunction[Int, Boolean] = {
case i if i > 0 => i % 2 == 0
}
val liftedF = pf.lift
liftedF(-1)
//None: scala.Option
liftedF(1)
//Some(false): scala.Option
Thanks to the lifting instead of doing sth like this:
future.map { result => result match {
case Foo(foo) => ???
case Bar(bar) => ???
}
Scala allows us to do it in a simpler way:
future.map {
case Foo(foo) => ???
case Bar(bar) => ???
}
ImplicitNotFound
From the Scala docs:
class implicitNotFound extends Annotation with StaticAnnotation An annotation that specifies the error message that is emitted when the compiler cannot find an implicit value of the annotated type.
Let’s look at the example:
trait Serializer[T] {
def serialize(t: T): String
}
trait Deserializer[T] {
def deserialize(data: String): T
}
def foo[T: Serializer](x: T) = x
foo(42)
When we run this code we get a rather vague error message:

However, when we add a simple implicitNotFound annotation:
import annotation.implicitNotFound
@implicitNotFound("Cannot find Serializer type class for type ${T}")
trait Serializer[T] {
def serialize(t: T): String
}
@implicitNotFound("Cannot find Deserializer type class for type ${T}")
trait Deserializer[T] {
def deserialize(data: String): T
}
def foo[T: Serializer](x: T) = x
foo(42)
foo("text")
We get more meaningful errors:


Conclusion
Scala is really powerful and expressive language that I like very much. On the other hand, it takes quite some time to get really proficient in it. The tips presented in this post are rather basic but hopefully in the following posts we will dive into more advanced, functional aspects of the Scala language.
It is always a matter of common sense when we develop software in Scala to decide if we keep the code simple enough and easy to understand for other developers. This is very important to remember since using Scala we have the tool to make the code really complicated and not understandable.
With Scala it is even possible to break the GitHub linter: ContentType.scala 🙂